Processing Censored Water Quality Data
Jon.Harcum@tetratech.com and Erik.Leppo@tetratech.com
2024-10-28
Source:vignettes/Processing_Censored_Data.Rmd
Processing_Censored_Data.RmdPurpose
The purpose of this vignette is to demonstrate a workflow for
managing data sets that have censored data. In the context of water
quality data, we often think of censored values as water quality
measurements reported as not-detected, less-than the quantitation limit,
between detection limit and limit of quantitation to name a few. For
example, in water quality, the value “<0.5” is typically thought of
as left censored. In the truest statistical sense of the meaning,
left-censoring implies no knowledge about the lower bound; however, in
most water resource applications, zero is a common lower bound.
Therefore, a value “<0.5” should be thought of as a water quality
measurement having a lower and upper bound of 0 and 0.5, respectively.
This allow baytrends to rely on the survival
package which treats these values as “interval” censored data and are
referred to as Surv objects.
This vignette is divided into three primary sections. The first section describes the process of importing data from csv files into a dataframe with Surv objects. The second section is a more general workflow. The third section provides a list of miscellaneous functions and notes.
- Importing data from CSV files for baytrends
- baytrends data management workflow
- Miscellaneous functions and notes
1. Importing data from CSV files for baytrends
Importing CSV files that have censored data into R dataframes for analysis in baytrends is a critical data preparation step and involves two lines of code: 1) importing the CSV data into R and 2) converting water quality measurements with censored data to Surv objects (see below code).
Example code
library(baytrends)
df_in <- loadData(file = "ExampleData.csv")
df_Surv <- makeSurvDF(df_in)The remainder of this section discusses the above lines of code by way of example.
Discussion
Figure 1 represents a portion of data from an example CSV file. Note, there is no requirement for the CSV file to have the data stored in the column order shown. In this example, the three required fields: station, date, and layer are stored in the first three columns ([A]-[C]). Missing values for these columns are not permissable. The user can optionally include additional fields such as depth, time, etc.
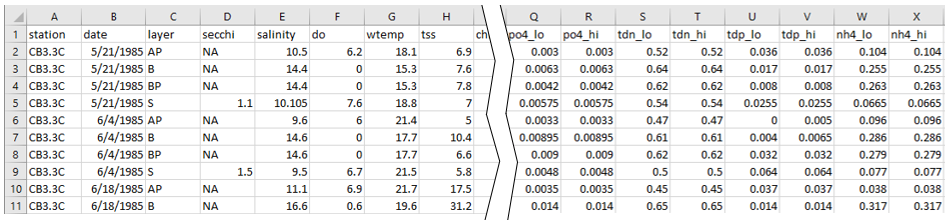
Figure 1. Example CSV file.
Fields with no censoring. In the above example, Secchi depth (secchi), salinity (salinity), dissolved oxygen (do), water temperature (wtemp), total suspended solids (tss) are stored in the next group of columns as un-censored data. While possible, censoring is less common for these types of water quality variables and as a result the data are represented with a single column in the CSV file. The values entered in these columns should be numeric values with no symbols. Values shown as “NA” are un-reported entries. Un-reported values can happen for a number of reasons including not being measured, equipment failure, etc. CSV files can use “NA” or use blanks to represent un-reported entries. Depending on the situation and the user’s sensitivity to fully evaluating censored data, a variable such as total suspended solids could be treated as an un-censored variable as shown in this example or could be treated as a variable with censored data as discussed next.
Fields with censoring. To the right of the break in Figure 1, water quality fields include lower and upper bounds to represent censoring. Note, the field naming syntax using a suffix of “_lo” and “_hi”. For example, columns [U] and [V] show the lower and upper bounds for total dissolved phosphorus as tdp_lo and tdp_hi, respectively. The upper bound must be greater than or equal to the lower bound. When the upper bound is equal to the lower bound, it indicates that observation did not have censoring.
loadData
The code df_in <- loadData(file = "ExampleData.csv")
uses a baytrends’ built-in function to load data from a CSV file.
Experienced R programmers can use other functions to load data
(e.g. read.csv, read.table); however,
loadData outputs meta data about the number of columns and
rows read and performs some useful steps such as converting date fields
into an R date field (i.e., POSIXct) and is advantageous
for further analyses with baytrends and other situations. There is also
a companion baytrends function, loadExcel, with similar
functionality to loadData and can be used to load data from
an Excel workbook. See help (i.e., ??loadData and ??loadExcel) for more
information.
makeSurvDF
After importing the above CSV file into an R dataframe, the next step
is to convert fields with censored data to Surv objects as depicted in
Figure 2 using the code df_Surv <- makeSurvDF(df_in).
Fields shaded in green or blue are column to column comparable to the
CSV file. Columns to the right of the break, such as the yellow
highlighted column, tdp, is a Surv object and is derived from the two
corresponding columns, tdp_lo and tdp_hi in the CSV file (Figure 1).
Again, experienced R programmers can make Surv objects independently
from baytrends by using the following syntax for each field with
censored data using the total dissolved phosphorus data as an
example.
df_in$tdp <- survival::Surv(df_in$tdp_lo, df_in$tdp_hi, type = "interval2") The baytends function, makeSurvDF, peforms this process
for all fields in a dataframe with censored data. By default,
makeSurvDF assumes the dataframe employs a suffix of “_lo”
to represent the lower bound and “_hi” to represent the upper bound
although this can be changed by the user. See help (i.e., ??makeSurvDF)
for more information. The makeSurvDF function also performs
a quality assurance review of the data to make sure the upper bound is
greater than or equal to the lower bound. The function outputs the
number of data integrity issues by parameter and sets those observations
to missing (NA) so the code can continue whilst the analyst determines
the appropriate corrective action.
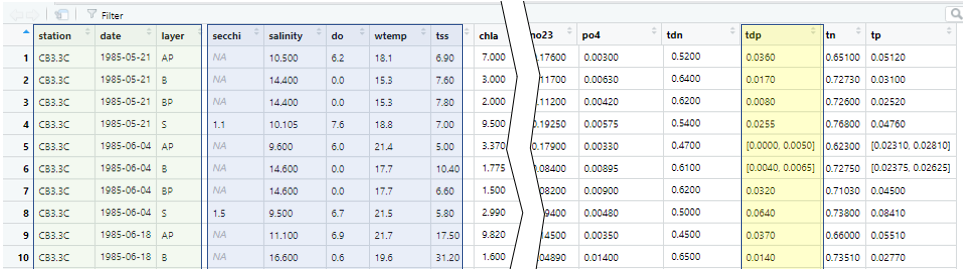
Figure 2. Example dataframe with Surv objects.
2. baytrends data management workflow
The previous section described the primary steps of importing CSV
files into R and converting fields with censored data to Surv objects
using the functions loadData and makeSurvDF.
Because many R functions do not recognize Surv objects, it may be
necessary to convert to Surv objects to standard numeric vectors for
some analyses. To address this need, baytrends includes two additional
functions, unSurvDF and saveDF to facilitate
extracting and saving lower and upper bounds from Surv objects. When
combined with the previously described functions, it is possible to have
a complete workflow as depicted in Figure 3. unSurvDF and
saveDF are described next.
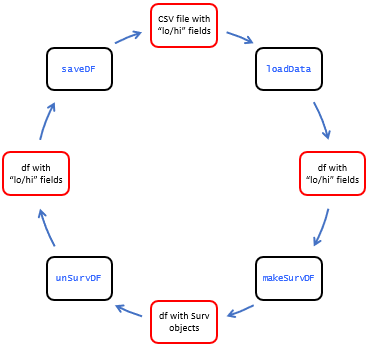
Figure 3. Workflow for handling censored water quality data with baytrends and Surv objects.
unSurvDF
As the name suggests, this function does the opposite of
makeSurvDF. That is, in the below example code,
df1 <- unSurvDF(df0), df0 is a dataframe with Surv
objects. unSurvDF passes through fields from
df0 that are not Surv objects and splits Surv objects into
two fields, the lower and upper bound, using a field naming syntax that
includes a suffix of “_lo” and “_hi”. The user can change the default
suffix (see help, i.e., ??unSurvDF for more information).
saveDF
This function saves a dataframe to a CSV file using a default naming
convention that includes the name of the dataframe and a timestamp in
the file name. In general, we have found that saving a dataframe that
includes Surv objects do not facilitate analyses in other software such
as Excel. As in the case of loadData it is straightforward
to use other functions to create csv files (e.g. write.csv,
write.table).
Example code
In the previous section, the sample code started at the top of the
diagram shown in Figure 3 and used loadData and
makeSurvDF to arrive at a dataframe with Surv objects as
shown at the bottom of the diagram. The example code in this section
starts at the bottom of the diagram and goes full circle such that the
dataframe df0 is identical to df3.
library(baytrends)
# Load the first 10 rows of the built-in baytrends dataframe
# dataCensored into a dataframe and just a few fields.
df0 <- dataCensored[1:10,c("station","date","layer","tss","tdp","tp")]
df0
# Convert the dataframe, df0, that has Surv objects to a
# dataframe where censored data are represented with
# "_lo/_hi" field name syntax.
df1 <- unSurvDF(df0)
df1
# Save dataframe, df1, where censored data are represented with
# "_lo/_hi" field name syntax to a csv file in the working
# directory.
saveDF(df1, folder = '.')
# Load data from csv file where censored data are represented
# with "_lo/_hi“ field name syntax to a dataframe of same
# structure.
df2 <- loadData("*.csv" ,folder = '.')
df2
# Convert dataframe, df2, where censored data are represented
# with "_lo/_hi“ field name syntax to a dataframe with Surv objects.
df3 <- makeSurvDF(df2)
df3Example output
library(baytrends)
#> Loading:baytrends v2.0.12
#>
#> Attaching package: 'baytrends'
#> The following object is masked from 'package:stats':
#>
#> nobs
# Load the first 10 rows of the built-in baytrends dataframe
# dataCensored into a dataframe and just a few fields.
df0 <- dataCensored[1:10,c("station","date","layer","tss","tdp","tp")]
df0
#> station date layer tss tdp tp
#> 1 CB3.3C 1985-05-21 04:00:00 AP 6.9 0.0360 0.05120
#> 2 CB3.3C 1985-05-21 04:00:00 B 7.6 0.0170 0.03100
#> 3 CB3.3C 1985-05-21 04:00:00 BP 7.8 0.0080 0.02520
#> 4 CB3.3C 1985-05-21 04:00:00 S 7.0 0.0255 0.04760
#> 5 CB3.3C 1985-06-04 04:00:00 AP 5.0 [0.0000, 0.0050] [0.02310, 0.02810]
#> 6 CB3.3C 1985-06-04 04:00:00 B 10.4 [0.0040, 0.0065] [0.02375, 0.02625]
#> 7 CB3.3C 1985-06-04 04:00:00 BP 6.6 0.0320 0.04500
#> 8 CB3.3C 1985-06-04 04:00:00 S 5.8 0.0640 0.08410
#> 9 CB3.3C 1985-06-18 04:00:00 AP 17.5 0.0370 0.05510
#> 10 CB3.3C 1985-06-18 04:00:00 B 31.2 0.0140 0.02770
# Convert the dataframe, df0, that has Surv objects to a
# dataframe where censored data are represented with
# "_lo/_hi" field name syntax.
df1 <- unSurvDF(df0)
df1
#> station date layer tss tdp_lo tdp_hi tp_lo tp_hi
#> 1 CB3.3C 1985-05-21 04:00:00 AP 6.9 0.0360 0.0360 0.05120 0.05120
#> 2 CB3.3C 1985-05-21 04:00:00 B 7.6 0.0170 0.0170 0.03100 0.03100
#> 3 CB3.3C 1985-05-21 04:00:00 BP 7.8 0.0080 0.0080 0.02520 0.02520
#> 4 CB3.3C 1985-05-21 04:00:00 S 7.0 0.0255 0.0255 0.04760 0.04760
#> 5 CB3.3C 1985-06-04 04:00:00 AP 5.0 0.0000 0.0050 0.02310 0.02810
#> 6 CB3.3C 1985-06-04 04:00:00 B 10.4 0.0040 0.0065 0.02375 0.02625
#> 7 CB3.3C 1985-06-04 04:00:00 BP 6.6 0.0320 0.0320 0.04500 0.04500
#> 8 CB3.3C 1985-06-04 04:00:00 S 5.8 0.0640 0.0640 0.08410 0.08410
#> 9 CB3.3C 1985-06-18 04:00:00 AP 17.5 0.0370 0.0370 0.05510 0.05510
#> 10 CB3.3C 1985-06-18 04:00:00 B 31.2 0.0140 0.0140 0.02770 0.02770
# Save dataframe, df1, where censored data are represented with
# "_lo/_hi" field name syntax to a csv file in the working
# directory.
saveDF(df1, folder = '.')
# Load data from csv file where censored data are represented
# with "_lo/_hi“ field name syntax to a dataframe of same
# structure.
df2 <- loadData("*.csv" ,folder = '.')
#>
#>
#> |Description |Value |
#> |:--------------------------------------|:--------------------------------|
#> |1) File Name |df1_2024_10_28_211722.317942.csv |
#> |2) Folder Name |. |
#> |3) Primary Key |NA |
#> |4) Rows Read In |10 |
#> |5) Columns Read In |8 |
#> |6) Rows After Blank Rows Removed |10 |
#> |7) Columns After Blank Columns Removed |8 |
#> |8) Rows After Duplicate Rows Removed |10 |
#> |9) Rows After Duplicate PK Removed |n/a |
df2
#> station date layer tss tdp_lo tdp_hi tp_lo tp_hi
#> 1 CB3.3C 1985-05-21 04:00:00 AP 6.9 0.0360 0.0360 0.05120 0.05120
#> 2 CB3.3C 1985-05-21 04:00:00 B 7.6 0.0170 0.0170 0.03100 0.03100
#> 3 CB3.3C 1985-05-21 04:00:00 BP 7.8 0.0080 0.0080 0.02520 0.02520
#> 4 CB3.3C 1985-05-21 04:00:00 S 7.0 0.0255 0.0255 0.04760 0.04760
#> 5 CB3.3C 1985-06-04 04:00:00 AP 5.0 0.0000 0.0050 0.02310 0.02810
#> 6 CB3.3C 1985-06-04 04:00:00 B 10.4 0.0040 0.0065 0.02375 0.02625
#> 7 CB3.3C 1985-06-04 04:00:00 BP 6.6 0.0320 0.0320 0.04500 0.04500
#> 8 CB3.3C 1985-06-04 04:00:00 S 5.8 0.0640 0.0640 0.08410 0.08410
#> 9 CB3.3C 1985-06-18 04:00:00 AP 17.5 0.0370 0.0370 0.05510 0.05510
#> 10 CB3.3C 1985-06-18 04:00:00 B 31.2 0.0140 0.0140 0.02770 0.02770
# Convert dataframe, df2, where censored data are represented
# with "_lo/_hi“ field name syntax to a dataframe with Surv objects.
df3 <- makeSurvDF(df2)
df3
#> station date layer tss tdp tp
#> 1 CB3.3C 1985-05-21 04:00:00 AP 6.9 0.0360 0.05120
#> 2 CB3.3C 1985-05-21 04:00:00 B 7.6 0.0170 0.03100
#> 3 CB3.3C 1985-05-21 04:00:00 BP 7.8 0.0080 0.02520
#> 4 CB3.3C 1985-05-21 04:00:00 S 7.0 0.0255 0.04760
#> 5 CB3.3C 1985-06-04 04:00:00 AP 5.0 [0.0000, 0.0050] [0.02310, 0.02810]
#> 6 CB3.3C 1985-06-04 04:00:00 B 10.4 [0.0040, 0.0065] [0.02375, 0.02625]
#> 7 CB3.3C 1985-06-04 04:00:00 BP 6.6 0.0320 0.04500
#> 8 CB3.3C 1985-06-04 04:00:00 S 5.8 0.0640 0.08410
#> 9 CB3.3C 1985-06-18 04:00:00 AP 17.5 0.0370 0.05510
#> 10 CB3.3C 1985-06-18 04:00:00 B 31.2 0.0140 0.027703. Miscellaneous functions and notes
Combining data frames that contain Surv objects
It is reasonable to assemble newly collected data with previous data in an environment outside of R and import the data en masse as described earlier. However, this step can also be performed inside R.
Normally, dataframes can be appended by using rbind
function within R. For dataframes that include Surv objects is is
necessary to use the bind_rows function from the
dplyr library as demonstrated in the below code.
Example code
library(baytrends)
#library(dplyr)
# Create two dataframes with Surv objects.
df11 <- dataCensored[1:10,c("station","date","layer","tss","tdp","tp")]
df11
df12 <- dataCensored[11:20,c("station","date","layer","tss","tdp","tp")]
df12
# Combine the two dataframe into one dataframe
df13 <- dplyr::bind_rows(df11,df12)
df13Example output
library(baytrends)
#library(dplyr)
# Create two dataframes with Surv objects.
df11 <- dataCensored[1:10,c("station","date","layer","tss","tdp","tp")]
df11
#> station date layer tss tdp tp
#> 1 CB3.3C 1985-05-21 04:00:00 AP 6.9 0.0360 0.05120
#> 2 CB3.3C 1985-05-21 04:00:00 B 7.6 0.0170 0.03100
#> 3 CB3.3C 1985-05-21 04:00:00 BP 7.8 0.0080 0.02520
#> 4 CB3.3C 1985-05-21 04:00:00 S 7.0 0.0255 0.04760
#> 5 CB3.3C 1985-06-04 04:00:00 AP 5.0 [0.0000, 0.0050] [0.02310, 0.02810]
#> 6 CB3.3C 1985-06-04 04:00:00 B 10.4 [0.0040, 0.0065] [0.02375, 0.02625]
#> 7 CB3.3C 1985-06-04 04:00:00 BP 6.6 0.0320 0.04500
#> 8 CB3.3C 1985-06-04 04:00:00 S 5.8 0.0640 0.08410
#> 9 CB3.3C 1985-06-18 04:00:00 AP 17.5 0.0370 0.05510
#> 10 CB3.3C 1985-06-18 04:00:00 B 31.2 0.0140 0.02770
df12 <- dataCensored[11:20,c("station","date","layer","tss","tdp","tp")]
df12
#> station date layer tss tdp tp
#> 11 CB3.3C 1985-06-18 04:00:00 BP 21.30 0.0160 0.0353
#> 12 CB3.3C 1985-06-18 04:00:00 S 29.10 0.0260 0.0486
#> 13 CB3.3C 1985-07-09 04:00:00 AP 12.00 0.0270 0.0488
#> 14 CB3.3C 1985-07-09 04:00:00 B 20.80 0.0400 0.0539
#> 15 CB3.3C 1985-07-09 04:00:00 BP 9.45 0.0180 0.0419
#> 16 CB3.3C 1985-07-09 04:00:00 S 12.20 0.0190 0.0562
#> 17 CB3.3C 1985-07-24 04:00:00 AP 16.40 0.0150 0.0490
#> 18 CB3.3C 1985-07-24 04:00:00 B 17.00 0.0470 0.0560
#> 19 CB3.3C 1985-07-24 04:00:00 BP 34.60 0.0430 0.0580
#> 20 CB3.3C 1985-07-24 04:00:00 S 16.60 0.0145 0.0490
# Combine the two dataframe into one dataframe
df13 <- dplyr::bind_rows(df11,df12)
df13
#> station date layer tss tdp tp
#> 1 CB3.3C 1985-05-21 04:00:00 AP 6.90 0.0360 0.05120
#> 2 CB3.3C 1985-05-21 04:00:00 B 7.60 0.0170 0.03100
#> 3 CB3.3C 1985-05-21 04:00:00 BP 7.80 0.0080 0.02520
#> 4 CB3.3C 1985-05-21 04:00:00 S 7.00 0.0255 0.04760
#> 5 CB3.3C 1985-06-04 04:00:00 AP 5.00 [0.0000, 0.0050] [0.02310, 0.02810]
#> 6 CB3.3C 1985-06-04 04:00:00 B 10.40 [0.0040, 0.0065] [0.02375, 0.02625]
#> 7 CB3.3C 1985-06-04 04:00:00 BP 6.60 0.0320 0.04500
#> 8 CB3.3C 1985-06-04 04:00:00 S 5.80 0.0640 0.08410
#> 9 CB3.3C 1985-06-18 04:00:00 AP 17.50 0.0370 0.05510
#> 10 CB3.3C 1985-06-18 04:00:00 B 31.20 0.0140 0.02770
#> 11 CB3.3C 1985-06-18 04:00:00 BP 21.30 0.0160 0.03530
#> 12 CB3.3C 1985-06-18 04:00:00 S 29.10 0.0260 0.04860
#> 13 CB3.3C 1985-07-09 04:00:00 AP 12.00 0.0270 0.04880
#> 14 CB3.3C 1985-07-09 04:00:00 B 20.80 0.0400 0.05390
#> 15 CB3.3C 1985-07-09 04:00:00 BP 9.45 0.0180 0.04190
#> 16 CB3.3C 1985-07-09 04:00:00 S 12.20 0.0190 0.05620
#> 17 CB3.3C 1985-07-24 04:00:00 AP 16.40 0.0150 0.04900
#> 18 CB3.3C 1985-07-24 04:00:00 B 17.00 0.0470 0.05600
#> 19 CB3.3C 1985-07-24 04:00:00 BP 34.60 0.0430 0.05800
#> 20 CB3.3C 1985-07-24 04:00:00 S 16.60 0.0145 0.04900Companion baytrends functions
unSurvDF and unSurv
As described earlier, unSurvDF converts dataframes that
contain Surv objects into dataframes with separate columns representing
the lower and upper bounds. The companion function, unSurv,
operates on a single field and returns a 3-column matrix as demonstrated
in the below code. See help (i.e., ??unSurv) for more information about
the returned columns.
dataCensored[1:10,c("station","date","layer","tss","tdp","tp")]
#> station date layer tss tdp tp
#> 1 CB3.3C 1985-05-21 04:00:00 AP 6.9 0.0360 0.05120
#> 2 CB3.3C 1985-05-21 04:00:00 B 7.6 0.0170 0.03100
#> 3 CB3.3C 1985-05-21 04:00:00 BP 7.8 0.0080 0.02520
#> 4 CB3.3C 1985-05-21 04:00:00 S 7.0 0.0255 0.04760
#> 5 CB3.3C 1985-06-04 04:00:00 AP 5.0 [0.0000, 0.0050] [0.02310, 0.02810]
#> 6 CB3.3C 1985-06-04 04:00:00 B 10.4 [0.0040, 0.0065] [0.02375, 0.02625]
#> 7 CB3.3C 1985-06-04 04:00:00 BP 6.6 0.0320 0.04500
#> 8 CB3.3C 1985-06-04 04:00:00 S 5.8 0.0640 0.08410
#> 9 CB3.3C 1985-06-18 04:00:00 AP 17.5 0.0370 0.05510
#> 10 CB3.3C 1985-06-18 04:00:00 B 31.2 0.0140 0.02770
unSurvDF(dataCensored[1:10,c("station","date","layer","tss","tdp","tp")])
#> station date layer tss tdp_lo tdp_hi tp_lo tp_hi
#> 1 CB3.3C 1985-05-21 04:00:00 AP 6.9 0.0360 0.0360 0.05120 0.05120
#> 2 CB3.3C 1985-05-21 04:00:00 B 7.6 0.0170 0.0170 0.03100 0.03100
#> 3 CB3.3C 1985-05-21 04:00:00 BP 7.8 0.0080 0.0080 0.02520 0.02520
#> 4 CB3.3C 1985-05-21 04:00:00 S 7.0 0.0255 0.0255 0.04760 0.04760
#> 5 CB3.3C 1985-06-04 04:00:00 AP 5.0 0.0000 0.0050 0.02310 0.02810
#> 6 CB3.3C 1985-06-04 04:00:00 B 10.4 0.0040 0.0065 0.02375 0.02625
#> 7 CB3.3C 1985-06-04 04:00:00 BP 6.6 0.0320 0.0320 0.04500 0.04500
#> 8 CB3.3C 1985-06-04 04:00:00 S 5.8 0.0640 0.0640 0.08410 0.08410
#> 9 CB3.3C 1985-06-18 04:00:00 AP 17.5 0.0370 0.0370 0.05510 0.05510
#> 10 CB3.3C 1985-06-18 04:00:00 B 31.2 0.0140 0.0140 0.02770 0.02770
unSurv(dataCensored[1:10,"tdp"])
#> lo hi type
#> [1,] 0.0360 0.0360 1
#> [2,] 0.0170 0.0170 1
#> [3,] 0.0080 0.0080 1
#> [4,] 0.0255 0.0255 1
#> [5,] 0.0000 0.0050 3
#> [6,] 0.0040 0.0065 3
#> [7,] 0.0320 0.0320 1
#> [8,] 0.0640 0.0640 1
#> [9,] 0.0370 0.0370 1
#> [10,] 0.0140 0.0140 1imputeDF and impute
In some instances, it is useful to simplify Surv objects to a single
field instead of lower and upper bounds. By default impute
and imputeDF will compute the midpoint between the lower
and upper bound for a single Surv field or convert the entire dataframe,
respectively as demonstrated with the below code. See help (i.e.,
??imputeDF and ??impute) for more information on other imputation
options including “lower”, “upper”, “mid”, “norm”, and “lnorm”.
dataCensored[1:10,c("station","date","layer","tss","tdp","tp")]
#> station date layer tss tdp tp
#> 1 CB3.3C 1985-05-21 04:00:00 AP 6.9 0.0360 0.05120
#> 2 CB3.3C 1985-05-21 04:00:00 B 7.6 0.0170 0.03100
#> 3 CB3.3C 1985-05-21 04:00:00 BP 7.8 0.0080 0.02520
#> 4 CB3.3C 1985-05-21 04:00:00 S 7.0 0.0255 0.04760
#> 5 CB3.3C 1985-06-04 04:00:00 AP 5.0 [0.0000, 0.0050] [0.02310, 0.02810]
#> 6 CB3.3C 1985-06-04 04:00:00 B 10.4 [0.0040, 0.0065] [0.02375, 0.02625]
#> 7 CB3.3C 1985-06-04 04:00:00 BP 6.6 0.0320 0.04500
#> 8 CB3.3C 1985-06-04 04:00:00 S 5.8 0.0640 0.08410
#> 9 CB3.3C 1985-06-18 04:00:00 AP 17.5 0.0370 0.05510
#> 10 CB3.3C 1985-06-18 04:00:00 B 31.2 0.0140 0.02770
imputeDF(dataCensored[1:10,c("station","date","layer","tss","tdp","tp")])
#> station date layer tss tdp tp
#> 1 CB3.3C 1985-05-21 04:00:00 AP 6.9 0.03600 0.0512
#> 2 CB3.3C 1985-05-21 04:00:00 B 7.6 0.01700 0.0310
#> 3 CB3.3C 1985-05-21 04:00:00 BP 7.8 0.00800 0.0252
#> 4 CB3.3C 1985-05-21 04:00:00 S 7.0 0.02550 0.0476
#> 5 CB3.3C 1985-06-04 04:00:00 AP 5.0 0.00250 0.0256
#> 6 CB3.3C 1985-06-04 04:00:00 B 10.4 0.00525 0.0250
#> 7 CB3.3C 1985-06-04 04:00:00 BP 6.6 0.03200 0.0450
#> 8 CB3.3C 1985-06-04 04:00:00 S 5.8 0.06400 0.0841
#> 9 CB3.3C 1985-06-18 04:00:00 AP 17.5 0.03700 0.0551
#> 10 CB3.3C 1985-06-18 04:00:00 B 31.2 0.01400 0.0277
impute(dataCensored[1:10,"tdp"])
#> [1] 0.03600 0.01700 0.00800 0.02550 0.00250 0.00525 0.03200 0.06400 0.03700
#> [10] 0.01400